

The most important thing for AI in 2026
What is overlooked when building modern machines


Most people will be focusing on the wrong things when it comes to AI in 2026.
Most people will be focusing on the emerging paradigms, the new breakthroughs, or the next groundbreaking model claimed to be AGI.
They are wrong.
What is far more important is something that too often gets overlooked. Something that is lethally ignored until it is too late. Something that, if done well, unlocks the real power of AI in a way that is not only sustainable but beats 99% of the competition.
To build good AI products, it is a mistake to obsess over the latest and greatest models. Chip Huyen, an experienced computer scientist and author of AI Engineering: Building Applications with Foundation Models, makes this point exactly. For her, the things that actually contribute to better AI products are talking to users, building a more reliable platform, using better data, optimising for end-to-end workflows and writing better prompts.
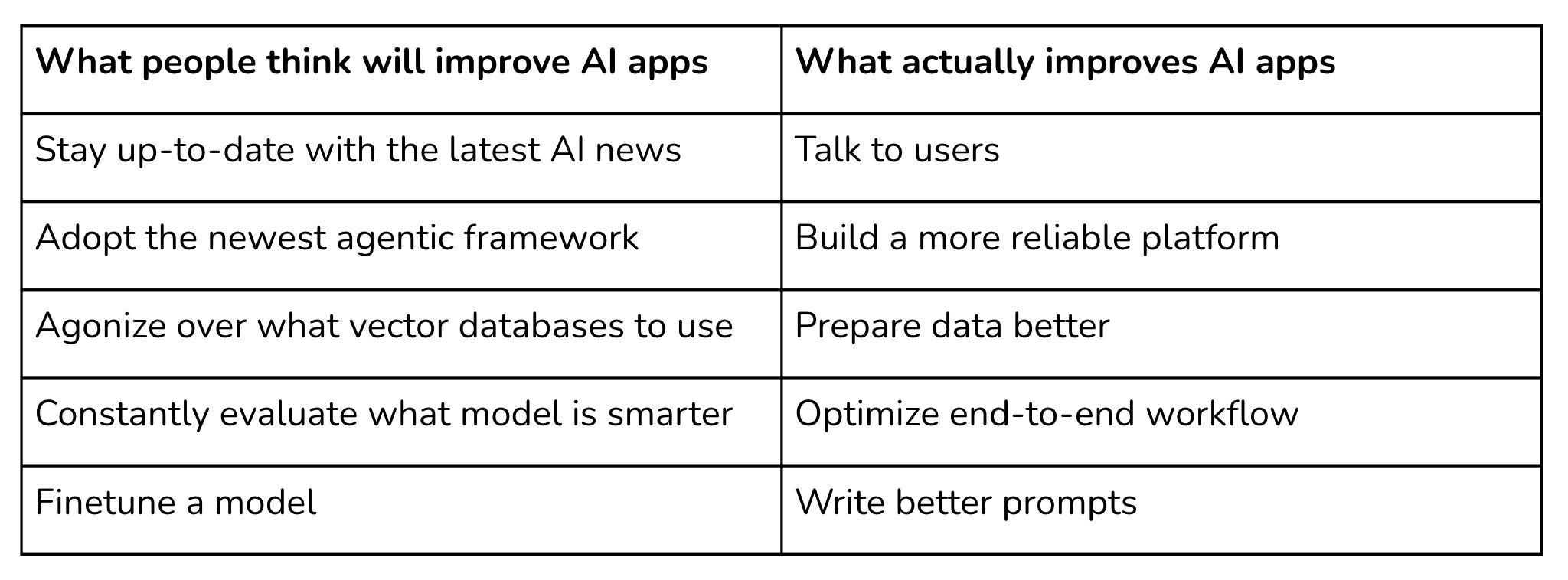
If you want customers to invest in your product, they need to be a position to trust your product. When the hype and bravado eventually fade away, trust is the currency that keeps customers around.
What all this means is that the most important thing for AI developers to focus on in 2026 and beyond is governance.
This is not because it is required by law. Or because it is a ‘nice-to-have’. Or even because it is good for PR.
Governance is a business-enabler. It is a way of deepening moats. It is the dynamic equilibrium that balances innovation and order.
Good governance is what underpins good, reliable AI products that actually work, build trust and deliver value.
As my last newsletter for 2025, I want to look to 2026 and what I think is next for AI from a data rights and governance perspective. I want to share what I think the AI landscape will probably look like, the problems it will produce, and why governance is the way to solve them.