

Why Your AI System Might Not Contain Personal Data (Even Though It Does)
A compliance strategy based on ignorance


The idea that LLMs ‘contain’ personal data was always an ambitious take.
Probably.
When I first looked at this topic a little over a year ago, I was not sure where I stood. I thought that the implications of concluding that models did not include personal data were simpler, thereby making that conclusion much more attractive. You can read my newsletter on this here:

If you have no idea what I am talking about, I explain everything in the newsletter linked above. But this is the gist:
LLMs are trained on lots of data, much of which is scraped from the internet
In that training data is lots information that would constitute personal data under the EU’s GDPR
There is an argument that, if that personal data is used for training the model, the resulting trained model ‘contains’ the personal data it was trained on
If the model contains personal data, and that model is used by another entity, then that entity may be processing personal data
The point made in my previous newsletter on this is that this is all quite complicated and I was never convinced one way or another; whether models do or do not contain personal data
But now my thoughts have evolved since the decision by the Court of Justice of the European Union (CJEU) in EDPS vs SRB, which I have also written about (twice):


That decision feels like a significant juncture in the development of EU data protection law that has ramifications for a number of data processing operations, including those pertaining to AI.
The SRB case clarified a point that even I thought was not up for debate: not all pseudonymised data is personal data. Even when I wrote about the Advocate General’s opinion on the case prior to the Court’s decision, I thought this might be one of the rare instances in which the CJEU would diverge from the AG.
I was wrong.
It turns out that there is nuance in data protection after all. Not all of it is rigid and strictly interpreted, and it allows for a flexibility that makes it workable in different contexts.
Perhaps this is a better way - such an approach to pseudonymisation probably makes sense.
If you encrypt some data, and share the cipher text with another entity without a copy of the cryptographic keys, the receiving entity does not have personal data in GDPR terms.
They have something that has been pseudonymised, but if they have no means to decrypt it, reverse engineer or otherwise transform the cipher text into its original form, then they just have unintelligible gibberish. Or at least they have information that could not be linked to any person and therefore identify a particular person. There is no personal data there.
There are some who might say that this opens the door for compliance escapism. If the information I have received cannot be used to identify a person, even if indirectly, then I don’t need to bother with GDPR obligations. Why would I when the information is not personal data?
From this perspective, SRB opens up a new gateway for avoiding the perceived compliance headaches of one the EU’s flagship regulations. And this gateway may be something that deployers of AI system take full advantage of.
Here is what I am getting at: if we take the principle from SRB and apply it to the question of whether AI models contain personal data, the answer is...still complicated.
If you look under the hood of a model, you could point to some parts and say, ‘yep, that is definitely personal data.’ But then there might be other parts where this is not the case.
The reason for this is because AI models are not like databases. It is not the internet indexed and searchable through a chat interface. Not at all.
The way model’s ‘store’ information is much different. If you look under the hood, you will see a probability distribution with fragments of words with their embeddings all numerically represented with no obvious organisation or structure.
The only way you could possibly argue that there is personal data anywhere in that mess is if you can demonstrate that the model has memorised verbatim some of its training data and that memorised training data is personal data.
This is not a crazy idea. Systems like ChatGPT have previously shown the tendency to do this kind of memorising and spit out personal data buried deep in its massive text corpus. This includes phone numbers, email address, physical addresses and more.


But to expose this vulnerability, you need the right prompt. You need a specific prompt attack that reveals the relevant personal data that the model may have memorised.
This leads to the critical next question - what are the prompts that do this? Or in SRB terms, what means would a deployer of AI systems have to extract and process the personal data contained in the system? How does a deployer know which personal data have been memorised and therefore can be extracted with the right prompt?
If you could not tell by now, this post is a very nerdy data-protection-crosses-technical-realities deep dive akin to what I did when I first looked at this issue of model’s containing personal data.
So all the details may not be all that exciting, but if you are a deployer of AI systems, whether its ChatGPT, Claude, Grok or others, then the thrust of this piece is highly relevant:
The SRB decision invites a compliance strategy based on ignorance; AI system deployers intentionally depriving themselves of the means to ‘re-identify’ any personal data in the model they are using.
It is a big take, but nevertheless a realistic one that is worth exploring. And in the remainder of this post, I attempt to explain it in the simplest way possible so that you can really understand both the point I am making, why I am making it and the implications it has for organisations using AI systems built by others.
As always, if you find this content useful, share it.
Let’s dive in.
The SRB principle
Pseudonymised data is not always personal data.
Now I think it is first of all worth explaining the concept of ‘personal data’ and what it actually means in the world of GDPR.
Simply put, ‘personal data’ means information that can be used to identify a person.
So personal data is not information that might be considered, in some colloquial sense, personal or sensitive. Sometimes when I hear people talking about personal data, they put emphasis on the personal so as to mean information that is particularly special, unique or intimate for the person it belongs to.
It certainly can be, but the concept of personal is much wider than that.
To really understand this, it is important to break the definition of personal data down into its constituent parts:
any information
relating to
identified or identifiable
natural person
Any information literally means any information, and this can be objective or subjective information about someone. Think names, email addresses, phone numbers but also opinions, assessments or even predictions about a person.
To be personal data, that information needs to be about an individual. This means that either the content, purpose or effect of the information must be linked to a particular person:
The content element is satisfied if the information itself is about an individual, such as the exam result of a student
The purpose element is satisfied if the information can be used to evaluate or analyse an individual
The effect element is satisfied if the use of the information has an impact on an individual’s rights or interests
To be identified or identifiable is about whether the entity holding the information can use it to single out a person from other people. I will come back to this later on.
Finally, a natural person is just a legal term for a person. So personal data does not include information about a corporation or organisation or anything that is not a human. The GDPR also does not apply to deceased persons.
With a sufficient understanding of personal data, we can then turn to the concept of pseudonymised data.
Generally, a pseudonym can be thought of as a cover name or a replacement for a true value or a kind of derivative of some original information. Pseudonymisation is therefore the process of taking data and applying some transformation to it that turns it into pseudonymised data.
Let’s say you have an email address: mahdiassan@email.com. If you wanted to pseudonymise this piece of information, there a couple a different ways you could do it.
You could pseudonymise the email address using a technique called masking whereby you simply replace certain characters in the address:
# masking_example
original_data = mahdiassan@email.com
pseudo_data = m********n@email.com
A more complicated way to pseudonymise the data is encrypt it whereby a cryptographic protocol is applied to the email which outputs some cipher text:
# encryption_example
original_data = mahdiassan@email.com
pseudo_data = 92edfa8361b7af3e637
This is where I want to return to the idea of identifiability.
Identifiability exists on a spectrum. On the one end, you have data points that directly identifies a specific individual (like a name) and on the other end you have data points that only indirectly identify individuals (like a userID). It is important to remember two things here though:
Indirect identifiability includes data points that can be linked to a person even if it is not known exactly who that person is
Anonymity is the complete opposite of direct identifiability - this where data cannot be linked to any person at all (as can be the case with aggregated statistics)
Pseudonymisation is about reducing the identifiability of personal data. It reduces the identifiability of data such that it can no longer be used to identify a specific individual. In other words, without the use additional information, it would be difficult to identify exactly who the pseduonymised data relates to.
Let’s go back to the encryption example above. When you encrypt data, you produce cipher text but also a set of cryptographic keys. These keys can be used to encrypt as well as decrypt the data. So if I encrypted some data and shared only the cipher text with someone else, and I kept the keys to myself, it would be very difficult for that person to use that data to identify someone - all they have is a hash value that bascially looks like a bunch of gibberish (92edfa8361b7af3e637).
However, a question one may have is, even if the person I shared the data with only has the cipher text, is that cipher text still personal data? After all, the keys to decrypt the data, and turn it back into its original form (mahdiassan@email.com), are still in my hands and therefore I still have the ability to see the personal data that has been encrypted. But regarding the third party I have shared only the cipher text with, what are they holding?
There are two different approaches to this question: a strict approach and a relative approach.
Under the strict approach, the cipher text in the hands of the third party is still personal data. That the cryptographic keys are in still existence, and therefore could be used by me to decrypt the data and link it to an individual, means that the encrypted data is still ultimately personal data. The means of identification are still there.
The relative approach, however, adds some nuance to this. Though the means for identification exist, it does not mean that the person that the data relates to is always identifiable. This depends on the means available to the person holding the information in question.
For a while, the strict approach seemed to be a dominate view among the data protection community. But a judgment from the CJEU in EDPS vs SRB last year has declared something different; that the relative approach should be taken regarding the concept of personal data.
I will not go over the case details again in this post; you can read all that in my previous post on the topic. But what I will reiterate here are the principles that can be derived from SRB.
Using my encrypted data example again, if I share only the encrypted data with the third party, and that third party has no access to the cryptographic keys, then, from the perspective of that third party, they are not holding personal data. This is as long as the following is true:
The third party cannot ‘lift’ the pseudonymisation (or in this case the encryption) preventing re-identification
The third party cannot perform re-identification through cross-checking with other available information it may have access to (including information it can search on the internet)
The risk of identification is insignificant considering the cost, time and the technology available
Accordingly, from the position of the third party with whom I share the encrypted data with, they are not holding personal data because:
They do not have the cryptographic keys to decrypt the data
There is no other information they can use to perform re-identification using the cipher text only (i.e., they cannot reverse-engineer the cipher text)
If I use a sufficiently complex cryptographic protocol, they cannot reproduce the cryptographic keys needed to decrypt the data (maybe barring access to a sufficiently powerful quantum computer)
The key thing to understand from SRB is that the nature of personal data’s relativity ultimately depends on the entity holding it. In essence, whether pseudonymised is personal data depends on who is looking at it and what they can do with it, not just on the data’s inherent properties.
Applying SRB to AI systems
I used the example of encrypted data earlier because it has a particular relevance to the second part of my thesis, which is about what is inside an LLM.
LLMs are giant prediction machines. They take your natural language input and spit out something that they think you need.
But if you look under the hood of an LLM, it is complex to say the least. It consists of tokenisers, embedding layers, positional encoders, transformer blocks and a probability distribution.
If you want a detailed explanation of how LLMs work, you can go back to my previous post:
But for now, the key point I make in that post is that the type of information that LLMs ‘store’ and the nature of that storage is not like how we traditionally think of data stored in databases.
When an LLM is being trained, internally it is building something called a vocabulary (or a vocab). This part of the model contains all the tokens it has come across in its training. A token represents a word of a fragment of a word in a numerical form (e.g., ‘computer’ might be tokenised to 2886). Additionally, each token will have assigned to it a word embedding, which encodes the tokens relationship with all the other tokens in the vocabulary.
So every time you give a model a prompt, it will refer to its vocab and work out the probability of each token being the appropriate tokens for the response to the prompt. And then it will select those tokens that are more likely to form the right output.
This vocab consists of a matrix that does kind of look like a table:
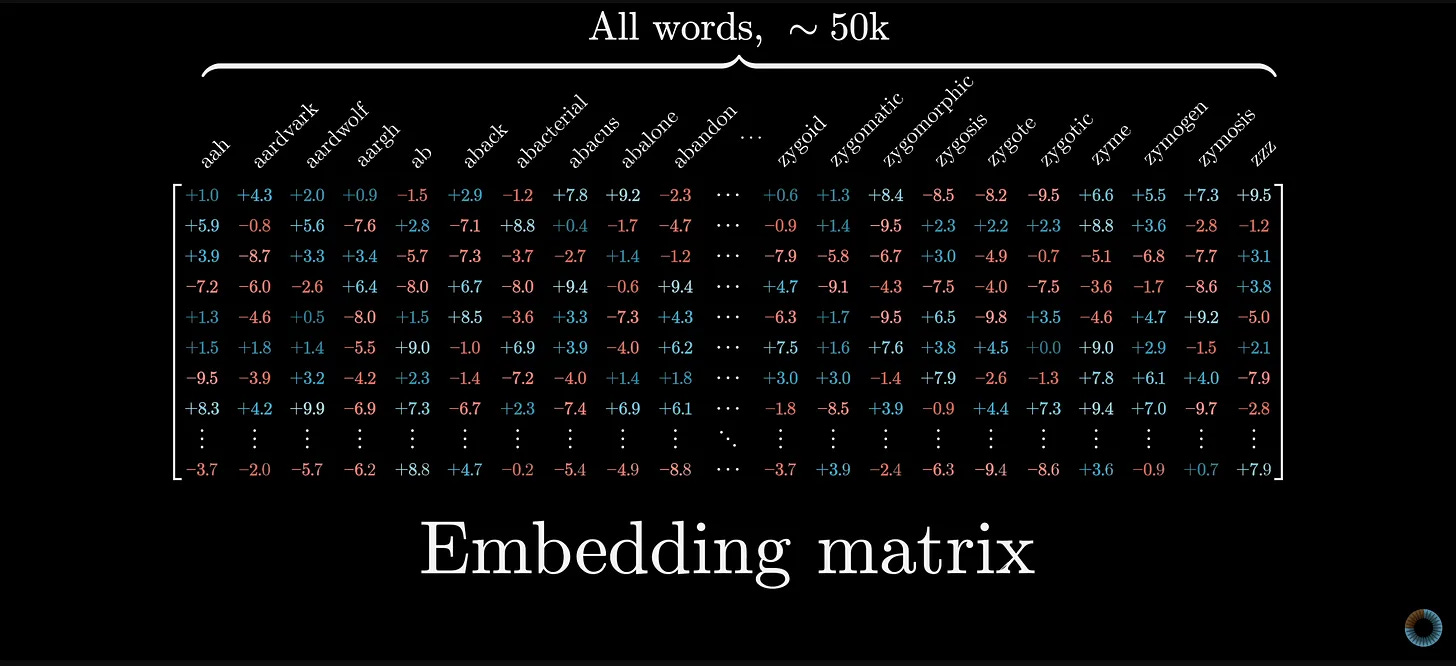
An LLM’s vocab can be very large - tens of thousands worth of tokens. This means that the matrix could have tens of thousands of columns representing each token along with tens of thousands of rows of values representing the word embeddings for each token.
But this matrix is not a database. The information in the vocab consists of values for the parameters that are learned during training, and those values codify the relationships between all the tokens that the model comes across during training (and this is in addition to the weights stored in the neural networks of each transformer block).
So altogether then, an LLM stores:
All the tokens it comes across during training
The embedding vectors for each token
The weights for the neural networks in each transformer block
This information does not itself relate to an identifiable natural person. It is a bunch of numbers that humans cannot comprehend. And even if we could comprehend these numbers, linking that back to particular people whose personal data may be in the training data would still be incredibly difficult.
In effect, all you have inside an LLM is a matrix of seemingly random numbers that are only readily interpretable to the LLM.
Looking inside an LLM to identify the personal data contained in there is no use. However, deconstructing the black box that is an LLM is not how most people interact with such digital artefacts. Most people interact with LLMs by prompting the text box on their screen.
Now this is where the encryption analogy comes in.
LLMs sometimes memorise verbatim the data they comes across during training. This does not happen with all the data points, but there is research out there showing that they are capable of doing this.
After training on a large dataset of text, the LLM has an understanding of language in the sense that it understands the correlations and patterns between words. However, the model does not necessarily learn factual information about the language it learns.
Any “factual knowledge” that the model is able to produce is merely derived from its understanding of language and the correlations between different words (or tokens). So by understanding language, it is possible for LLMs to “learn” factual information.
In particular, such factual information could be learned if the relevant patterns appear frequently enough in the training dataset. The more often the model comes across a certain pattern during training, the more prominently that pattern will be represented in its parameters.
Whenever the model then receives an input containing text relating to that more frequent pattern, it will rely on that pattern to produce its response. In doing so, the model could produce data that it has essentially ‘memorised’ from its training data.
So while the information contained within LLMs is not intelligible to humans, the personal data that is in there somewhere and has been memorised by the model could be extracted by prompting the model in certain ways.
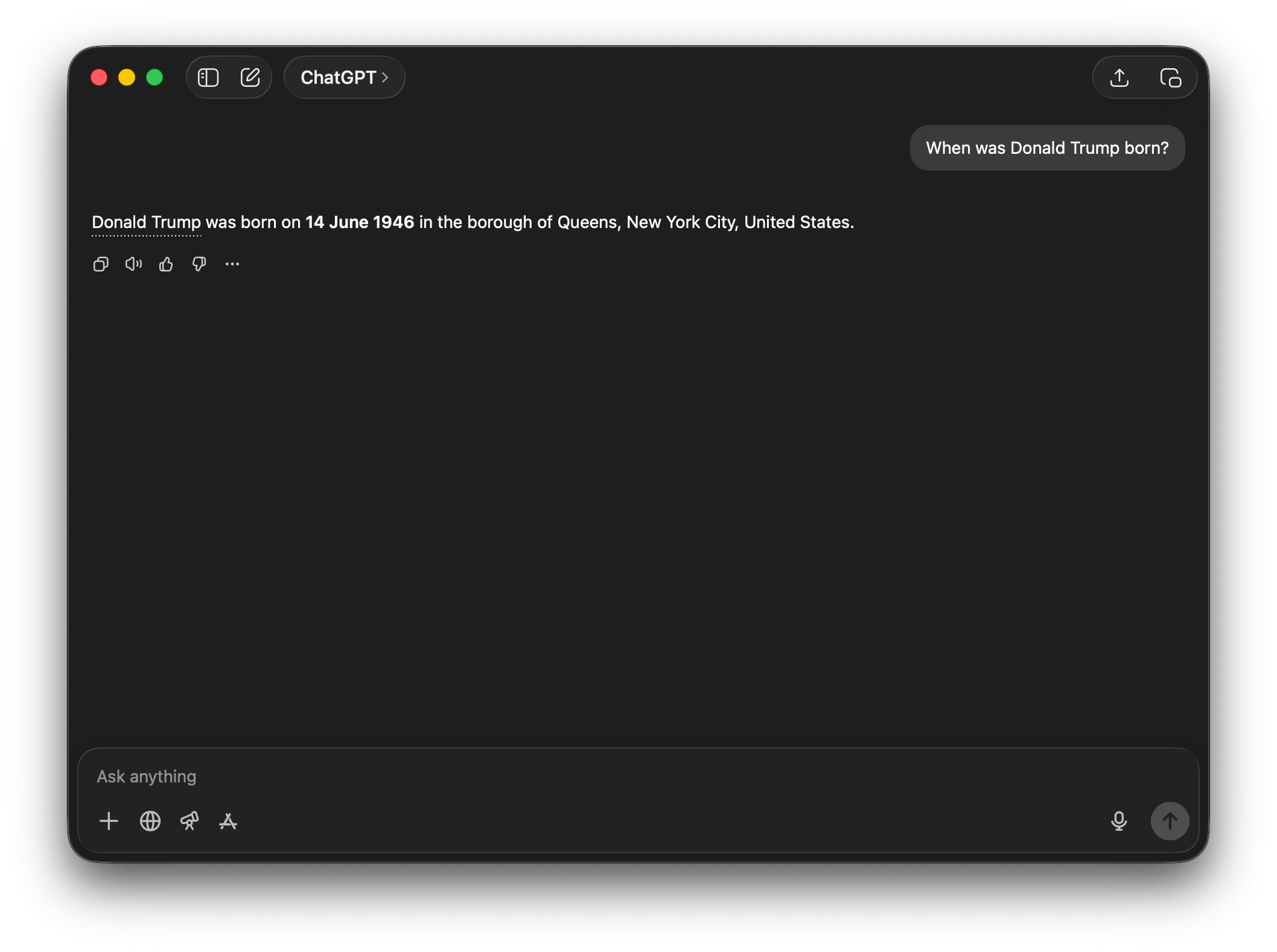
If I ask ChatGPT when Donald Trump was born, it says he was born on 14 June 1946:
But if I ask ChatGPT who was born on 14 June 1946, I get this:
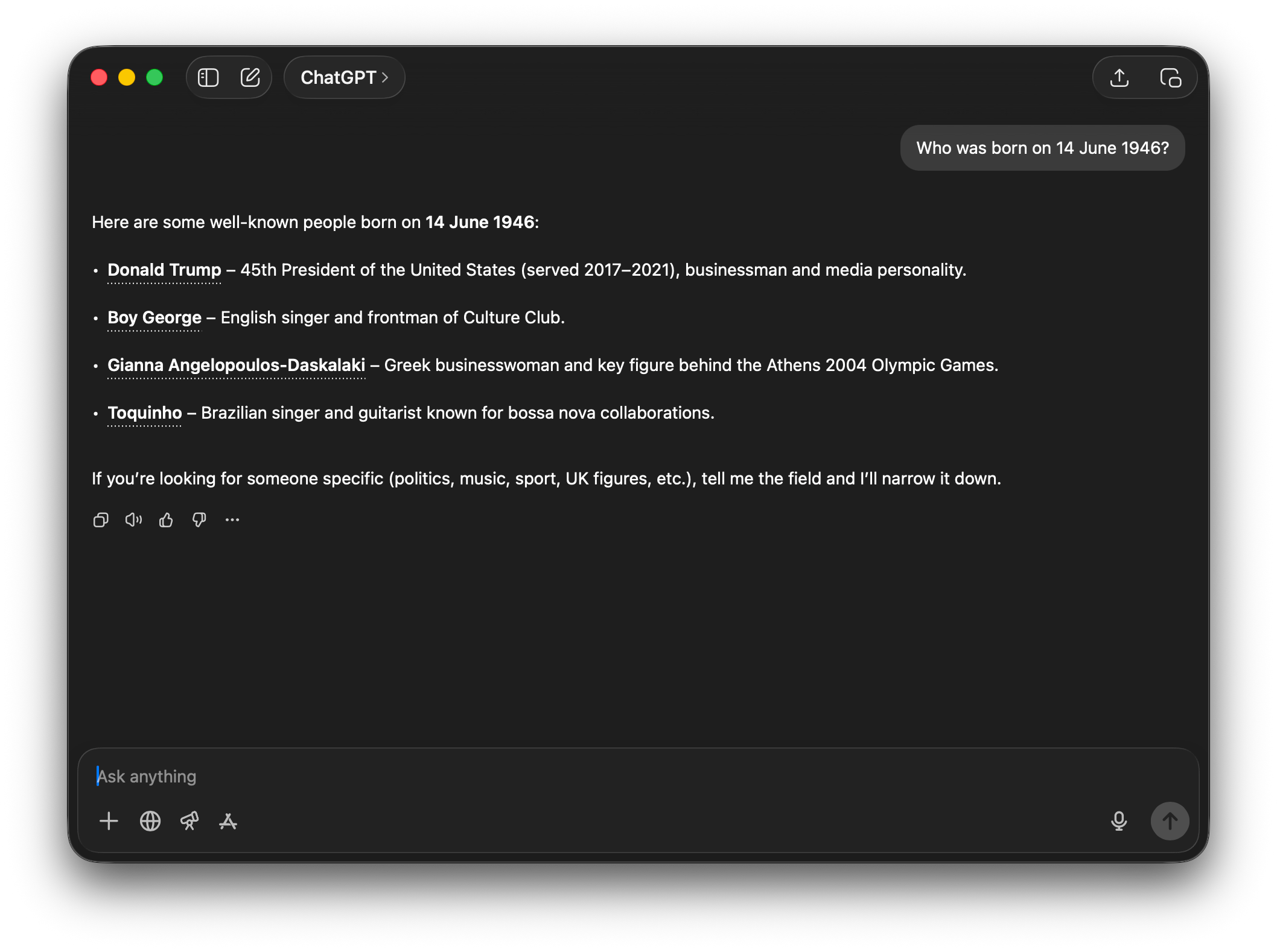
Clearly ChatGPT has learned from is training data that “14 June 1946” and “born” and “Donald Trump” are all strongly associated with each other, hence why I get the outputs I do.
Obviously though the prompts for extracting this information are pretty straight forward here given that Donald Trump, or any other public figure, will likely feature multiple times in the training data. This increases the propensity of the LLM to memorise certain information about such figures and therefore increases the ease of which such information can be extracted through prompting.
But the point here is that personal data that has been memorised by the model can be transformed from an unreadable to a readable format by using the right prompt. Which is similar to the how encryption works.
Recall that with encryption, you have:
The original data
The cryptographic protocol applied to the data
The generation of the encrypted data
A set of cryptographic keys that can decrypt the encrypted data back to the original data
And you could describe LLMs and personal data extraction in a similar way:
Personal data is contained in the large training datasets consisting of data scraped from the internet
That data are tokenised and mapped to word embeddings
The data are therefore converted into a bunch of values representing these tokens and embeddings and organised into a matrix
With the right prompt, that unintelligible bunch of numbers can effectively be converted into readable text that may constitute personal data
With this logic, the information you have inside LLMs is pseduonymised data. The tokens and word embeddings are in a pseudonymised form as a result of model training, and then transformed into intelligible personal data if the right prompt is used with the model at inference.
Extending this, if a developer takes a trained LLM and incorporates it into a new product, then that developer will not necessarily be holding personal data. Applying the SRB principle, the developer is only holding personal data extractable from the model if they use the means to extract it, which would be the prompts.
But if the developer does not know what those prompts are and does not use them, then that extractable, memorised personal data remains pseudonymised. The GDPR obligations that would therefore otherwise apply (selecting an appropriate legal basis, adhering purpose limitation and data minimisation etc) are not of concern to the developer regarding the pseudonymised personal data ‘inside’ the model it is incorporating into its product.
I would argue that this perspective on the matter is reinforced by a compliance strategy that has been implicitly endorsed - a strategy based on ignorance.
Compliance based on ignorance
I want to be clear about a couple of things here before I go on explaining this take.
Firstly, I am not saying that this potential compliance strategy is right in the sense of it is a good thing. But I do predict that this will be a strategy that many developers will be tempted towards because it makes their compliance work simpler.
Secondly, this potential compliance strategy does not absolve developers of all of their data protection responsibilities. This only absolves them from the needing to address data protection issues arising from the use of the model or building on top of it - the personal data contained in these models is not their responsibility. However, the way that the system they are building using the model processes personal data is still their problem, and data protection responsibilities definitely still apply there. This is the case regarding personal data used to develop the system or personal data collected when people use the system, but neither of these processing operations are the subject of this post.
The compliance strategy explored in this piece specifically concerns developers using trained models to build new products - do those products already contain personal data by using a model trained with lots of personal data that might be ‘stored’ in the model?
I argued in the last section that these models do not necessarily contain personal data. In this section, I look at how developers could go about demonstrating this by essentially remaining ignorant about the details of the models they are using.