


Notes on LLMs and influence operations
Notes on LLMs and influence operations
Some of the potential dangers of generative AI


TL;DR
These are notes on a report produced through a collaboration between OpenAI, the Stanford Observatory (SIO) and Georgetown's Center for Security and Emerging Technology (CSET). The report is about large language models (LLMs), like the infamous ChatGPT, and the prospect of such models being used for influence operations.
In particular, the report attempts to explore the following question:
How might language models change influence operations, and what steps can be take to mitigate these threats?
The report was produced as a result of a workshop in October 2021 involving several experts in AI and influence operations discussing the potential impact of LLMs on influence operations.
One important note to highlight about the arguments made in the report is that there is a degree of speculation regarding what LLMs may be capable of in the future, and how this may impact influence operations:
A paper on how current and future technological developments may impact the nature of influence operations in inherently speculative. Today, we know that it is possible to train a model and output its content - without notifying social media users - on platforms. Likewise, existing research shows that language models can produce persuasive text, including articles that survey respondents rate as credible as real news articles. However, many of the future-oriented possibilities we discuss in the report are possibilities rather than inevitabilities, and we do not claim any one path will necessarily come to fruition. (Goldstein et al 2023, 8)
However, I would argue that the potential threats posed by LLMs as described in the report lean more towards very likely possibilities as opposed to merely speculative. The advances in LLMs in the last few years have been tremendous, and the exploration of various use cases is only in the beginning stages.
During the World Economic Forum 2023, Satya Nadella explained how Microsoft would be incorporating AI tools into its suite services in Azure, including ChatGPT from OpenAI which the tech company plans to invest billions of dollars into. See also this blog post from Microsoft on the extension of its partnership with OpenAI.
This connects to two ways of thinking about LLMs and their impact, as articulated by François Chollet (Keras creator and Google AI researcher):
Idea 1: "When I first made the claim that in a not-so-distant future, most of the cultural content that we consume will be created with substantial help from AIs, I was met with utter disbelief, even from long-time machine learning practitioners. That was in 2014." (Chollet 2021) And look where we are now...
Idea 2 (the caveat): replacing humans with AI is not really the point. It is not "about replacing our own intelligence with something else, it's about bringing into our lives and work more intelligence - intelligence of a different kind. In many fields, but especially creative ones, AI will be used by humans as a tool to augment their own capabilities: more augmented intelligence than artificial intelligence." (Chollet 2021)
Bringing this back to influence operations, this report by Goldstein and others shows how (i) LLMs have advanced enough that their potential to make influence operations more scalable and potent is (very) real, and (ii) this does not mean that LLMs completely do away with the need for a human-in-the-loop but can improve influence operations simply by being used as tools for augmenting existing practices.
Here on Substack,
has written about the difference between cognitive automation and cognitive autonomy, and how current AI models fall in the former category and that thus AI models capable of true cognitive autonomy still remains "stuff of science fiction."These notes follow the structure of the report:
Section 2 contains an overview of influence operations, including what they are and how they work
Section 3 looks at recent developments generative models, but with a focus on LLMs
Section 4 combines the previous sections to show how LLMs can be used for more scalable and potent influence operations
Section 5 sets out a range of mitigation measures to address the risks presented by influence operations using LLMs
Section 6 contains the conclusions of the report
If you enjoy, consider subscribing and feel free to leave any questions and thoughts in the comments below.
Section 2: Influence operations
What are influence operations?
The report defines 'influence operations' as "covert or deceptive efforts to influence the opinions of a target audience." (Goldstein et al 2023, 9) The aim here is to either:
Provoke targets with particular beliefs
Persuade targets of particular viewpoints
Distract the target
Any influence operation often involves at least one of four tactics to achieve one of the above aims:
Present a government, culture or policy in a positive light
Advocate against specific policies
Make allies look good and adversaries/rivals looks bad to third-parties
Destabilise foreign relations or domestic affairs
The accounts created on social media to execute these tactics will "masquerade as locals expressing discontent with their government or certain political figures." (Goldstein et al 2023, 9)
An example of this is Russia's Internet Research Agency (IRA) accounts: they "pretended to be Black Americans and conservative American activists, and directly messaged members of each targeted community." (Goldstein et al 2023, 10)
What impact are influence operations intended to have?
Influence operations can have an impact in two main ways:
Impact based on content:
This happens when the content either (i) persuades a target of a certain opinion or reinforces an existing one, (ii) distracts a target from finding/developing other ideas, or (iii) distracts a target from higher quality thought.
Often persuading the target by the information deployed is not as important as preventing the target from being "persuaded by (or even consider) some other piece of information." (Goldstein et al 2023, 11)
An example: "In 2016, the IRA used manipulative agents of influence on Facebook to provoke real-world conflict by organizing protests and counter-protests outside the Islamic Da'wah Center in Houston." (Goldstein et al 2023, 12)
Downstream impact based on trust:
This is where identifying influence operations can have the strange effect of causing people to doubt other authentic sources of information
This can easily be done by mixing inauthentic material with authentic material to help blur any distinction between the two
In doing so, perpetrators "often aim to exploit vulnerabilities in their target's mental shortcuts for establishing trust, especially where information technologies make it harder to evaluate the trustworthiness of sources." (Goldstein et al 2023, 13)
The downstream impact is therefore an overall loss of trust, and trust in society in particular: "Lower societal trust can reduce a society's ability to coordinate timely responses to crises, which may be a worthy goal for adversarial actors in and of itself." (Goldstein et al 2023, 14)
Overall, the desired impact of influence operations is to influence (i.e., change) the mind of the target audience in favour of the interests/aims of the perpetrator. Such activity reveals why data protection is so important:
Influence operations represent attempts at decisional interference; this is about intruding into a person's decision-making regarding their private affairs
The aim of data protection is to ensure that people's data are being used in a responsible and ethical manner
This means data protection has different purposes, for example protecting people's privacy by maintaining the confidentiality of information that people do want to share with people or only want to share with certain people
But another purpose of data protection that is relevant to influence operations is to protect one's autonomy and self-determination
This point stands regardless of whether the attempts to influence are successful or not (though see notes just below). People should have the ability to think for themselves without undue influence and the opportunity to know when they are being unduly influenced and to prevent such activity
Limitations of influence operations
The report makes the important point that actually measuring the impact/effectiveness of these influence operations is difficult.
This is because it is a question of causation; is there a causal relationship between the operation and the target's viewpoint?
Part of the difficulty is identifying/measuring the manifestation of the target's change in viewpoint; is it through engagement metrics (clicks, likes, shares etc) or through how targets vote in an election?
Even with this resolved, "where a clear comparison group does not exist [to set up the counterfactual comparison], it can be difficult to determine how viewing or engaging with content translates into important political outcomes like polarization or votes." (Goldstein et al 2023, 12)
Despite the difficulties in measuring impact, however, there are a range of factors that can limit the effectiveness of influence operations:
Resources - the more resources available to a campaign, the better positioned it is to generate and disseminate content to its target audience
Content quality - the content of messages disseminated needs to confirm the target's attitudes/beliefs, blend in with their information environment and provide high-quality and convincing arguments
Detectability - if the operations are discovered by social media platforms, those platforms will take them down
Section 3: Generative models
The report provides a condensed summary of what LLMs are:
These machine language systems consist of large artificial neural networks and are "trained" via a trial-and-error process over mountains of data. The neural networks are rewarded when their algorithmically generated words or images resemble the next word in a text document or a face from an image dataset. The hope is that after many rounds of trial and error, the systems will have picked up general features of the data they are trained on. After training, these generative models can be repurposed to generate entirely new synthetic artifacts. (Goldstein et al 2023, 15)
But what does all this mean?
What are large language models?
These are deep learning models (thus ML models using neural networks) that generate novel text using large datasets of text data that it has been trained on.
ChatGPT is the one the most popular examples of LLMs right now. This is a system developed by OpenAI that uses a LLM to create a chatbot that interacts with users in a conversational way. OpenAI have published a detailed blog explaining how it works, but the notes below attempt to explain LLMs in a (hopefully) more accessible way.
How are LLMs even possible?
The answer is simple:
Language and artwork have a statistical structure that can be observed and learned, including by a machine
Deep learning algorithms excel at learning statistical structures; this is what they are built for
In particular, they are capable of taking a piece of artwork/text, identifying the statistical latent space, sampling from this space, and then using that to 'create' new artworks similar to that which it has seen in its training data
The idea that text data has a statistical latent space relies on a concept known as the manifold hypothesis:
This hypothesis is one of the most important ideas underpinning deep learning algorithms
It puts forward the idea that data lies on a manifold, essentially an encoded subspace
This subspace is continuous
This therefore means that all the samples in the subspaces are connected
If all the subspaces are connected, then you can take one sample in the subspace, and make several little changes until that sample looks like another sample from the same subspace
Take the MNIST dataset of handwritten digits as an example; if you take one digit from the dataset (let's say the digit 3), you can make a number of small iterative visual changes to the digit until it starts to resemble another digit in the dataset (like the digit 6). This is shown in the diagram below:

This manifold hypothesis applies to all sorts of data types, including natural language data. This is therefore how LLMs are able to process text data as an input and generate new text.
How have LLMs been able to advance so much recently?
Recent advances in LLMs (and deep learning models in general) have been down to three main factors:
Data - "the explosion of training data in the form of human language available on the internet (and in curated datasets of interest or user-generated content)." (Goldstein et al 2023, 18)
Algorithms - "improvements in the underlying neural network models and the algorithms used to train them." (Goldstein et al 2023, 18)
Computing power - "rapid growth in the amount of computational power that leading actors have used to train these models, which allows for the creation of larger, more sophisticated models." (Goldstein et al 2023, 18)
Thus:
More high quality data + better algorithms + increased computing power = high-performing deep learning models
LLMs and text generation
Modern LLMs use generative transformers to process text data (hence, 'GPT' stands for generative pre-trained transformers). For example, GPT-3 from OpenAI uses a generative transformer with 175 billion parameters trained on a very large dataset sourced from books, Wikipedia articles and crawling the internet.
The transformers process text data by capturing the latent space (or the statistical structure) of the natural language in the training data. It does this by taking an input (the prompt) and predicting the next token or few tokens in a sequence:
Tokens in this context represent words or characters
The network is working out the probability of the next token given the previous tokens (i.e., the input or prompt)
A model that does this is called a language model
Once you have trained the model, you:
Feed it an initial string of text (aka the conditioning data)
Ask it to generate the next character or the next word
Add the generated output back to the input data
Repeat this process many times
For example, if you input into the model "The cat sat on the ", it will use the learning it gained from its training data to predict the next word. This prediction will form its output, which could be 'mat', and use this to complete the sentence: "The cat sat on the mat."
The predictions for the next possible word based on the input/prompt are sourced from the probability distribution generated by the model based on its learning from the training data:
Based on the training data that the model has learned about, for each input it will identify the probabilities of each of the possible next tokens (or words), and these probabilities represent the probability distribution
To ensure that the model comes up with seemingly creative outputs, engineers can introduce randomness into how the model selects the next words based on the prompt. This is known as stochastic sampling (stochasticity means randomness in the context of deep learning). Using this technique, the model will not merely select words with a high probability in the probability distribution but will instead vary its selection between different words with different probabilities. As such, randomness is being used as a proxy for creativeness.
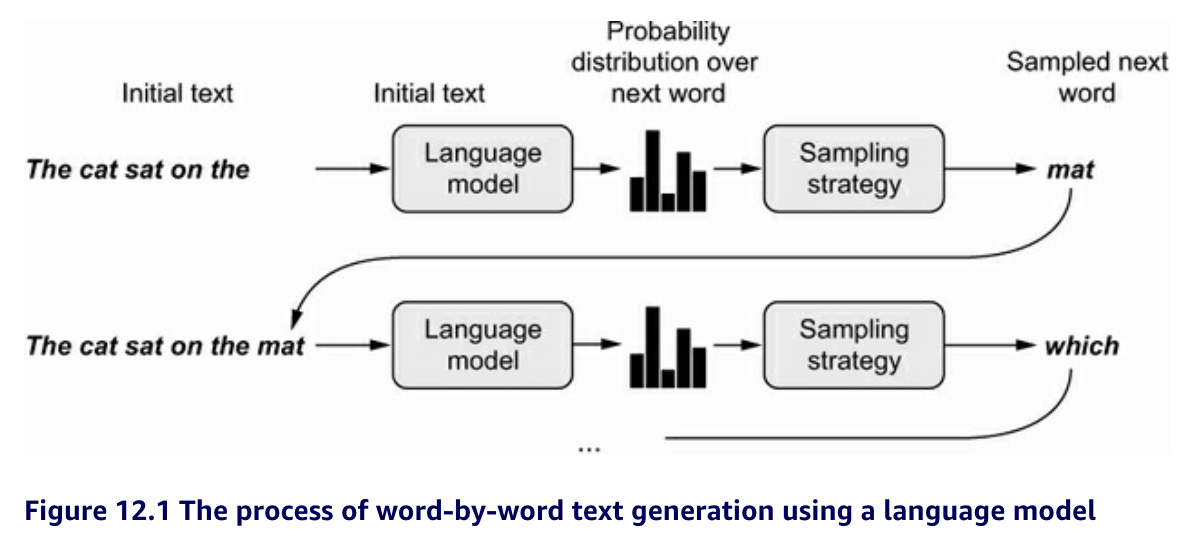
But for LLMs like ChatGPT, the model will be a sequence-to-sequence model. This means that, instead of just predicting the next word, the model will predict a set of next words to create complete sentences or even paragraphs.

So this is how LLMs like ChatGPT work:
They are models that predicts "a probability distribution over the next word in a sentence, given a number of initial words. When the model is trained, [it will take as an input] a prompt, sample the next word, add that word back to the prompt, and repeat, until [it generates] a short paragraph." (Chollet 2021)
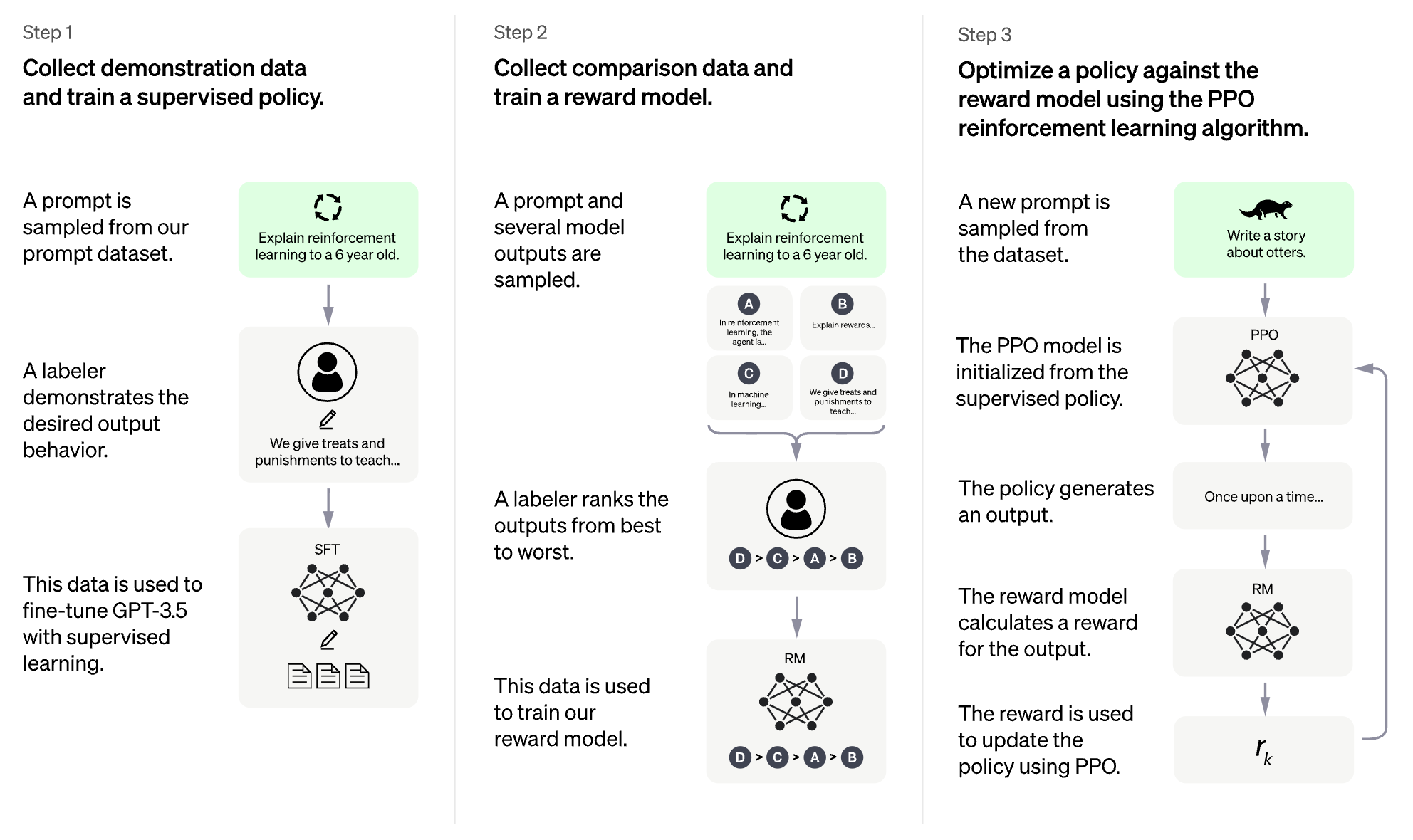
You can even take this a step further by training the model not just using text data collected in the dataset, but by also having humans rank the quality of the different suggested outputs of the model and feeding that back into training loop. This is what OpenAI did to train ChatGPT, which is why its outputs can seem so frighteningly accurate (though not always truly accurate). See step 2 in particular in the diagram below:
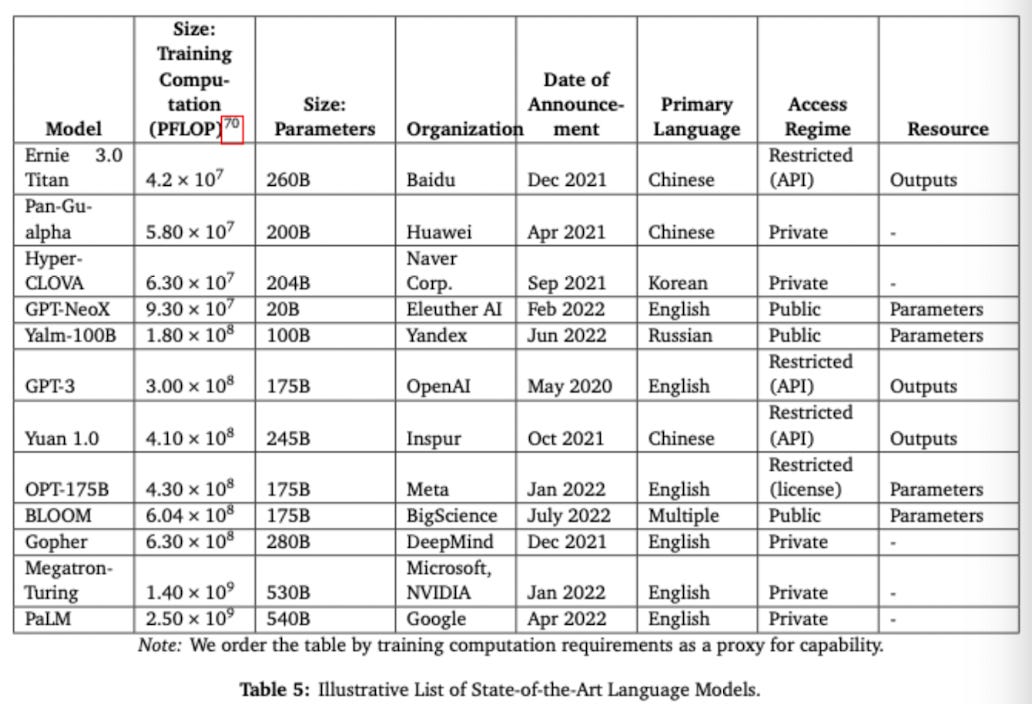
The report outlines the known LLMs today and the level of access each have (among other pieces of information on each):
(LLMs from OpenAI and others have come a long way in the last few years. It means that they have moved on from some of the less accurate, and even comical, outputs that earlier iterations would produce. See the video below for a funny example of this.)
The gatekeeper problem
Moving away from technical aspects of LLMs, the report makes an important point about the capabilities of different models that currently exist:
...the relative capabilities of different language models tends to correspond to the amount of computational power used to train them, and more computational power generally (though not always) means a larger model with more parameters. It is therefore worth emphasizing that the largest fully public model is two to three times smaller than the largest currently existing private models. (Goldstein et al 2023, 19)
The most capable LLMs are therefore in the hands of a few private companies, such as OpenAI. As such, the development of the most capable LLMs, and their potential use in a range of different contexts, including influence operations, to a large extent lies in the control of these companies (as well as those with enough resources to augment publicly-accessible models):
...anyone can access a number of moderately capable models that have been made fully public, but the most capable models remain either private or kept behind monitorable APIs. While currently publicly available models may not be as powerful as the largest private models, they can likely be fine-tuned to perform remarkably well on specific tasks at far less cost than training a large model from scratch. This type of fine-tuning might not be within the reach of most individuals, but it is likely feasible for any nation-state as well as many non-state actors, such as firms and wealthy individuals. (Goldstein et al 2023, 20)
Section 4: Influence operations + LLMs
The report uses the ABC framework (ABC) to explore how LLMs could impact future influence operations:
Actors (i.e., the 'who'): these are not always who they seem to be; "for example, the accounts in a conversation may look like Black Lives Matter activists, but in reality may be state-linked actors using fake accounts in active misdirection." (Goldstein et al 2023, 22)
Behaviour (i.e. the 'how'): this is about "the techniques used to perpetuate disinformation, such as the use of automation or attempts to manipulate engagement statistics via click farms." (Goldstein et al 2023, 22)
Content (i.e., the 'what'): this is about "the substance (narrative, memes etc) that the accounts are attempting to launder or amplify." (Goldstein et al 2023, 22)
LLMs have the potential to impact each of these three aspects. The table below summarises these arguments in the report:

Actors
The idea here is simple: LLMs reduce the cost of running influence operations at scale. As a result, this expands the number of potential actors that can engage in such activities.
For example, "political actors are increasingly turning toward third-party influence-for-hire companies to conduct their campaigns, including firms that otherwise appear to be legitimate marketing or PR firms." (Goldstein et al 2023, 24)
Behaviour
There are a number of interesting points here:
Replacing or augmenting humans in the content generation process:
The report makes the argument that LLMs could potentially replace humans in the process of producing content for influence operations, resulting in lower cost and increased scalability.
But as was mentioned previously, it is not the case that LLMs are advanced enough, or ever will be advanced enough, to do away with the need for a human-in-the-loop. However, LLMs can certainly be used as a tool for augmentation, and still have the effect of lowering costs and increasing scalability.
Overwhelming tools designed to detect AI-generated content:
LLMs could "increase the scale and decrease detectability of similar future operations. In a recent field experiment, researchers sent over 30,000 emails - half written by GPT-3, and half written by students - to 7,132 state legislators. The researchers found that on some topics legislators responded to computer-generated content at only a slightly lower rate than human-generated content; on other optics, the response rates were indistinguishable." (Goldstein et al 2023, 25)
Leveraging demographic information to generate more targeted messaging:
Currently, this process is made difficult by the level of human capital required
But with the use of LLMs, this practice could produce this tailored content for several demographic groups at a scale that humans are incapable of.
"The payoff of this strategy depends on how persuasive AI-generated text is, and how much more persuasive highly tailored personalized text is, compared to one (or a few) human-written articles." (Goldstein et al 2023, 25)
Again, sticking to the theme of AI augmentation, humans could still be involved by making minor alterations to the outputs of the LLMs, which would still speed up the overall process.
Personalised chatbots:
These could be used to interact with targets 1-on-1 instead of disseminating content to large groups.
The could even form part of systems that serve as "interactive social media personas." (Goldstein et al 2023, 25)
These chatbots could also be used to manipulate other innocuous chatbots to spread propaganda (i.e., 'poison' other LLMs); the report cites Microsoft's Tay as an early example of this though more sophisticated attacks of this kind could be deployed in the future.
Content
LLMs could be used for both short-form content (like tweets or comments) or for long-form content (like news articles):
Short-form content:
This could be pushed to social media or the comments sections of websites/blogs with the intent of influencing the target's perception of public opinion; "Many tweets or comments in aggregate, particularly if grouped by something like a trending hashtag, can create the impression that many people feel a certain way about a particular issue or event." (Goldstein et al 2023, 26)
LLMs could be particularly advantageous in this context if they can outperform the bots that some currently try to deploy on social media platforms; "If propagandists can use generative models to produce semantically distinct, narratively aligned content, they can mask some of the telltale signs (identical, repeated messaging) that bot detection systems rely on - prompting bot detection systems to leverage other signals." (Goldstein et al 2023, 27) See below an example of how LLMs could be used to produce this convincing content to make even small groups seem larger than they actually are:

Long-form content:
Humans will need hours or days to produce news articles on a topic, while LLMs could produce the same or at least similar quality within seconds.
One technique that could be used here is known as 'narrative laundering'; "Russia's "Inside Syria Media Center" (ISMC) news website, a GRU front property whose bylined journalists included fabricated personas, produced content that was republished as contributed content within ideologically aligned, unwitting publications, or incorporated into real news articles in the context of expert quotes." (Goldstein et al 2023, 27)
This means that those operating influence campaigns can reduce cost, time, cognitive load and avoid hiring (many) real people who might otherwise jeopardise such operations.
The report also dives into some of the expected technological developments for LLMs and how this may also impact future influence operations, as summarised in the table below:
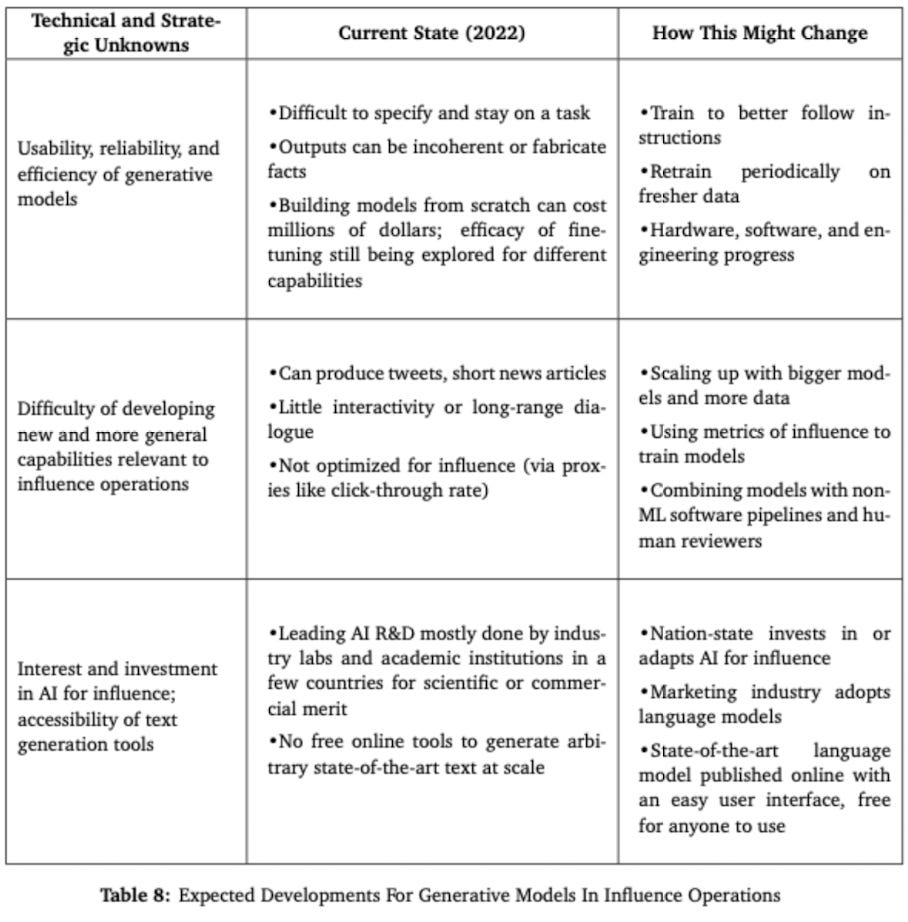
Looking at each of these technological developments:
Improvements in usability, reliability, and efficiency:
Over time, it can be expected that LLMs will improve in terms of usability, reliability and efficiency
On usability:
Whilst fairly usable currently, LLMs still require a fair degree of skill and experience to operate them in an optimal fashion for the particular task
As such, work is currently underway to make LLMs even easier to operate for users in general
For example, "researchers have tried tagging different parts of the training data by their types (e.g., "dialogue" would specify dialogue data), and then asking a model to only produce data of a certain type." (Goldstein et al 2023, 30)
"If usability of language models improves, propagandists will be able to use models for new tasks as they arise without in-depth prompt engineering experience." (Goldstein et al 2023, 30)
On reliability:
In the future, it is reasonable to expect the performance of LLMs to improve and thus increase their reliability (to the extent that they do not even require that much human monitoring when performing certain tasks).
In fact, it could be argued that improving the reliability of LLMs is imperative over time since they will need to keep up with the inevitable evolutions in language that will occur: "One reason why models fail to consistently produce high-quality text is because they lack awareness of time and information about contemporary events. The current training regime for generative models trains them once on a large corpus of data, which means that models will have not context for events that occur after this key moment. Ask a language system that was trained before COVID-19 about COVID-19, and it will simply make up plausible answers without any real knowledge about the events that unfolded." (Goldstein et al 2023, 31)
There are broadly two approaches to solving this: (i) retrain the model on new updated data, or (ii) create a model that is capable of targeted updates.
Such improvements would be welcomed by those executing influence operations since they will be looking to manipulate perceptions of breaking news stories and new information that emerges.
On efficiency:
There are many ways this could be improved: improved algorithmic models, upgrades in hardware, low-cost optimisation techniques for smaller models etc.
Even recently, "research has come out that claims to train GPT-3 quality models for less than $50,000, which would represent a factor of 3-10x improvement. If capabilities relevant to influence operations - generated persuasive text, fake personas, or altered videos - are achievable with significantly lower cost, then they are more likely to diffuse rapidly." (Goldstein et al 2023, 32)
New and more general capabilities for influence:
The report sets out two critical unknowns related to LLMs: (A) capabilities that will emerge as side effects of scaling to larger models, and (B) the difficulty of training models to execute tasks useful to influence operations
On (A):
The idea here is that advances in LLMs (such as the ability to predict the next word or pixel) could give rise to other adjacent, general capabilities
"A system trained to predict the next word of an input can also be used to summarize passages or generate tweets in a particular style; a system trained to generate images from captions can be adapted to fill in parts of a deleted image, and so on. Some of these abilities only emerge when generative models are scaled to a sufficient size." (Goldstein et al 2023, 33)
Additionally, "improvements in reasoning capabilities might also allow generative models to produce more persuasive arguments." (Goldstein et al 2023, 33)
In essence, while LLMs may be scaled and improved for one intended purpose, the advancements achieved could be utilised for other, perhaps unintended, purposes (a type of unintentional function creep in a way)
On (B):
It is plausible that propagandists might try to configure LLMs to be better for tasks like persuasion and social engineering
This could be achieved through improved targeted training of the models: "Generative models could be trained specifically for capabilities that are useful for influence operations. To develop these capabilities, perpetrators may choose to incorporate signals such as click-through data or other proxies for influence. These signals may be included in the training process, resulting in generative models more strongly optimized to produce persuasive text. Advertising and marketing firms have economic incentives to train models with this type of data, and may inadvertently provide the know-how for propagandists to do the same. Another form of targeted training would be to withhold or modify the information in the training data to affect how the trained model produces content. For example, suppose that a language model is trained with all mentions of a particular group occurring alongside false negative news stories. Then even innocuous deployments of products based on that language model - like a summarizer or customer support chatbot - may produce slanted text without being transparent to model users." (Emphasis added) (Goldstein et al 2023, 33)
Another method could be to combine LLMs with other automated processes: LLMs could form the engine for intelligent bots that imitate human-like behaviour and deploy this system on a platform like Facebook: "For example, a propagandist could write software to find and copy the Facebook profiles of people with interests compatible with the propaganda message, and use this to prompt the generative model." (Goldstein et al 2023, 34)
Wider access to AI capabilities:
There are three ideas presented in the report on this:
Increased investment - if more investment goes into the development of LLMs this could increase the likelihood that propagandists gain access to them
Unregulated tooling - the proliferation of LLMs could increase the adoption of these models for the purposes of influence operations
Intent-to-use LLMs for influence operations - "If social norms do not constrain the use of models to mislead, then actors may be more likely to deploy models for influence operations." (Goldstein et al 2023, p.35)
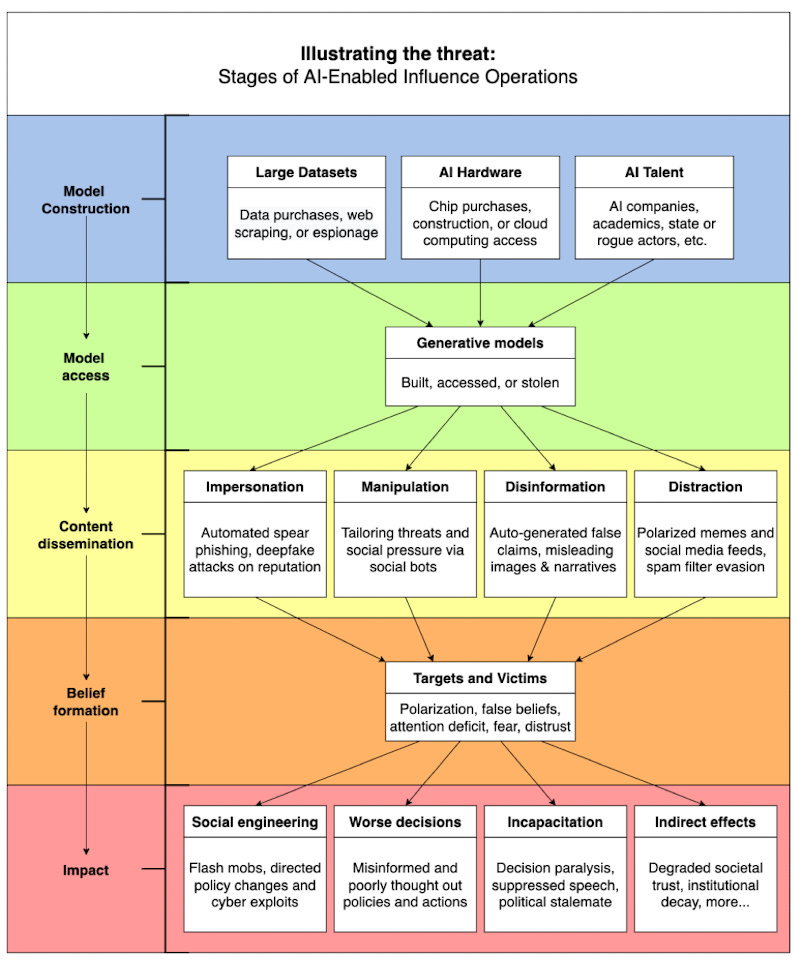
Section 5: Risk mitigation measures
The mitigation measures suggested in the report can be applied at various stages of the influence operation pipeline:
Model construction
Model access
Content dissemination
Belief formation
In addition, each measure is evaluated using four key considerations:
Technical feasibility - whether the measures is technically possible or feasible
Social feasibility - whether the implementation of the measure requires coordination between different stakeholders, whether key actors are incentivised to do so, and whether the measure is permissible under the relevant legal framework or consistent with industry standards
Downside risk - the negative externalities and second order effects
Impact - whether this addresses the risk
The table below summarises the mitigation measures proposed in the report:

Looking at some of the more interesting measures:
AI developers build models with more detectable outputs
Example 1 - Radioactive training data: Researchers at Meta have come up with ways to detect images produced with AI models that have been trained on 'radioactive data'; "images that have been imperceptibly altered to slightly distort the training process." (Goldstein et al 2023, 42)
Example 2 - Perturbations: slight manipulations to the output of the model could be intentionally introduced to help to distinguish that output from non-AI content. However, "as models become bigger and develop a richer understanding of human text, these detection methods break down if the parameters of the models themselves are not deliberately perturbed in order to enable detection." (Goldstein et al 2023, 43)
Further drawbacks of the above two methods (and any other method for creating detectable generative AI outputs) include: (a) linguistic data is already highly compressed and thus leaves little room for added perturbations, and (b) attackers may simply start using models that do not apply such manipulations to its outputs (and therefore high levels of coordination are required between developers to ensure that this measure is effective).
Edward Tian, a 22-year-old Princeton student, has developed an app that is able to detect whether an essay has been produced by a human or ChatGPT:

Governments impose restrictions on data collection
LLMs need huge amounts of training data in order to be effective; as mentioned before, this data is often sourced from books, Wikipedia articles and crawling the internet and scraping publicly available text
Any constraints on the collation of these training datasets would in turn put constraints on the development of LLMs
This could be achieved through laws like the GDPR; we still await an equivalent type of legislation in the US at Federal-level
The sale of data could also be addressed; "Such laws have occasionally resulted in successful legal action against AI developers, as when the ACLU successfully used BIPA to compel Clearview AI to screen out data from Illinois residents in its model training pipeline and to sharply limit access to its facial recognition tools within Illinois." (Goldstein et al 2023, 47)
AI providers impose stricter controls on language models
Most LLMs that are publicly available are accessible only through gated APIs; this provides a mechanism for imposing controls on their use, in particular through the following ways:
Requiring users to submit proposed purposes for which they intend to use the model for, and preventing/revoking access for unacceptable uses
Restricting access to only trusted institutions (e.g., known companies, research organisations or universities) and therefore exclude governments or other adversaries that may use the model for disinformation or other malicious purposes
Limiting the number of outputs that a user can generate with the model (or flag users making submissions over a certain threshold)
Restrict certain types of inputs, for example "the image-generating model DALL·E attempts to screen out user-submitted queries that are intended to produce "violent", adult or political" outputs." (Goldstein et al 2023, 50)
There are a few caveats to such measures: (i) restrictions requiring manual review may be difficult to implement at scale, (ii) the incentives of commercialisation may mean that developers forgo such restrictions in favour of more customers, (iii) coordination is required to ensure that these restrictions are applied to essentially all LLMs, otherwise propagandists will simply use those models with less restrictions, (iv) developers may run into issues with complying with relevant data protection laws whilst carrying out the type of monitoring required for some of these measures.
Platforms require "proof of personhood" to post
Some of the current practices used by social media to determine whether a user is actually human is to require real names and unique email addresses upon sign up, or even submitting 'video selfies'; CAPTCHA is often used as well
This would not prevent an adversary from simply copying-and-pasting AI-generated text from elsewhere though
Privacy considerations would also be relevant here: "user authentication requirements would likely face resistance from users who are accustomed to an expectation of anonymity online, including users who hold such expectations for very legitimate reasons." (Goldstein et al 2023, 56)
Final remarks
The report provides its main conclusions as follows:
Language models are likely to significantly impact the future of influence operations.
There are no silver bullets for minimising the risk of AI-generated disinformation.
New institutions and coordination (like collaboration between AI providers and social media platforms) are needed to collectively respond to the threat of (AI-powered) influence operations.
Mitigations that address the supply of mis- or disinformation without addressing the demand for it are only partial solutions.
More research is needed to fully understand the threat of AI-powered influence operations as well as the feasibility of proposed mitigations.
The main point here is that LLMs could be used for influence operations right now. But some argue that even the current generative AI models are only just the beginning, going as far as to suggest these models are merely precursors to artificial general intelligence (AGI):

However, not everyone agrees:

At least for now, as mentioned at the beginning of this post, AI augmentation seems a more realistic way to think about LLMs and generative models as opposed to thinking of them as forms of AI autonomy/AGI. But this is enough for them to provide sufficient utility for a range of tasks and activities, including influence operations.
Or proving the obvious:


Sources
Francois Chollet, Deep Learning with Python (2nd edn, Manning Publications 2021)